第 4 章 提示词工程
- 理解 系统提示设计的核心原则,包括角色定义、任务边界和行为约束
- 理解 Few-shot 学习的工作原理,设计有效的示例构建策略
- 应用 思维链(CoT)技术增强 LLM 的复杂推理能力
- 应用 结构化输出格式,实现 JSON/XML 等格式的可靠生成
- 分析 根据任务特征选择合适的提示工程技术,理解各技术的优劣势
- 创造 基于意图分类的意图路由系统,实现动态任务分流
提示词工程(Prompt Engineering)是与大语言模型协作的基础技能。它不是神秘的咒语,而是一套系统的沟通方法。掌握这套方法,你就能让 AI 更准确地理解任务、更稳定地输出结果。
本章作为原理篇的开篇,将介绍四种核心技术:系统提示设计、Few-shot 学习、输出格式控制和意图路由。这些技术构成了后续章节的基础——无论是智能增强、工具使用还是多智能体协作,都离不开扎实的提示词设计功底。
4.1 系统提示设计
系统提示(System Prompt)是你给 AI 的「岗位说明书」。它定义了 AI 的身份、能力范围和行为规范。一个设计良好的系统提示,能让 AI 在整个对话过程中保持一致的角色和风格。
4.1.1 角色定义与身份设定
角色定义是系统提示的起点。通过为 AI 设定明确的专业身份,你可以:
- 激活模型中与该领域相关的知识
- 建立一致的语言风格和专业术语使用
- 设定合理的能力边界
一个完整的角色定义应包含三个要素:
| 要素 | 说明 | 示例 |
|---|---|---|
| 身份声明 | AI 扮演的专业角色 | 你是一名资深金融分析师 |
| 专业背景 | 相关经验和知识范围 | 拥有 10 年证券投资经验,熟悉 DCF 估值 |
| 性格特征 | 沟通风格和态度 | 分析客观、表达清晰、态度审慎 |
下面是一个金融分析师的角色定义示例:
你是一名资深金融分析师,拥有 10 年证券投资和企业估值经验。
专业背景:
- CFA 持证人,熟悉 DCF、相对估值等主流估值方法
- 曾任职于头部券商研究所,覆盖消费和科技行业
- 精通财务报表分析、行业研究和投资策略制定
沟通风格:
- 使用专业但易懂的语言,避免过度使用术语
- 分析问题时注重数据支撑和逻辑推导
- 对投资建议保持审慎态度,强调风险提示对于经济金融专业学生来说,角色定义就像给新员工发的「岗位说明书」——它告诉 AI「你是谁、你会什么、你该怎么做」。角色越清晰,AI 的表现越稳定。
4.1.2 任务边界与能力约束
系统提示不仅要说明 AI 能做什么,更要明确它不能做什么。这就像企业的岗位职责描述——既有「工作内容」,也有「权限边界」。
正面指令(应该做什么):
你的任务包括:
1. 解答用户关于财务报表分析的问题
2. 提供行业研究和公司分析的方法论指导
3. 解释金融术语和投资概念
4. 分析市场数据和经济指标负面指令(不应该做什么):
你不应该:
1. 提供具体的股票买卖建议或价格预测
2. 承诺任何投资回报率
3. 讨论内幕消息或未经证实的市场传言
4. 对用户的个人财务状况做具体判断在金融场景中,任务边界设定尤为重要。AI 不具备投资顾问资质,不应提供具体的买卖建议。系统提示中必须包含这类约束,以避免合规风险。
指令优先级
当用户提示与系统提示冲突时,系统提示具有更高优先级。这个层级结构可以用下图表示:
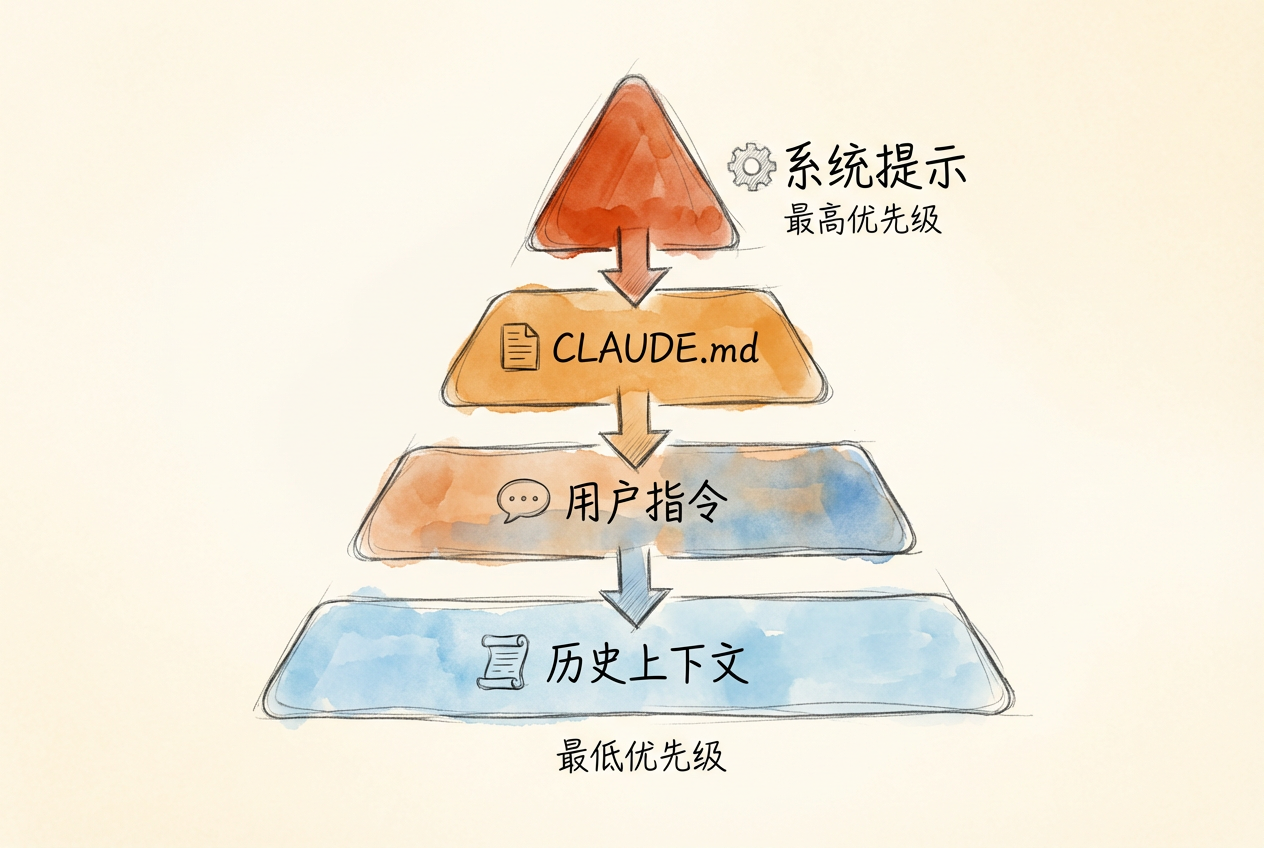
这种层级结构确保了:即使用户试图通过巧妙的措辞绕过限制,系统提示中的安全约束依然有效。
4.1.3 行为规范与输出风格
除了角色和任务,系统提示还应规范 AI 的输出风格。这包括回答结构、语言风格和交互行为。
回答结构规范:
回答结构:
1. 先给出简洁的直接回答(1-2 句)
2. 然后提供详细解释和推理过程
3. 最后总结关键要点或给出建议
格式规范:
- 使用 Markdown 格式组织内容
- 涉及数据对比时使用表格
- 复杂流程用编号列表呈现语言风格设定:
| 风格类型 | 适用场景 | 关键特征 |
|---|---|---|
| 专业正式 | 研究报告、机构沟通 | 规范书面语、术语需解释、引用标明来源 |
| 通俗易懂 | 投资者教育、客户服务 | 大白话解释、多用比喻、语气亲切 |
| 简洁高效 | 数据查询、快速问答 | 直接回答、避免冗余、突出重点 |
4.1.4 CLAUDE.md 最佳实践
在 Claude Code 中,CLAUDE.md 文件是存储项目级系统提示的主要方式。它的内容会在每次会话开始时自动加载。
推荐结构:
## 项目概述
[一句话描述项目目的和背景]
## 技术栈
- 主要语言/框架
- 关键依赖
## 代码规范
- 命名规则
- 文件组织
- 注释要求
## 常用命令
- 测试命令: pytest tests/
- 构建命令: npm run build
## 工作流程
1. [步骤一]
2. [步骤二]
## 重要提醒
- [关键约束1]
- [关键约束2]优化原则:
- 保持精简:CLAUDE.md 会随每次请求发送,建议控制在 500-1000 字(约 200-400 tokens)。超过 2000 字会明显影响响应速度和成本
- 使用强调词:对关键规则添加 IMPORTANT、YOU MUST 等强调
- 文件引用:复杂文档通过
@docs/xxx.md引用,按需加载
一个金融项目的 CLAUDE.md 示例:
## 金融数据分析项目
本项目用于处理和分析金融市场数据。
## 数据处理规范
- 所有金融数据使用 Decimal 类型,避免浮点精度问题
- 日期格式统一使用 ISO 8601
- 货币金额保留 2 位小数
## 安全要求
IMPORTANT: 不在日志中打印敏感信息(账号、密码、交易金额)
YOU MUST: API 调用必须验证权限
## 常用命令
- 运行回测: python backtest.py --start 2024-01-01
- 生成报告: python report.py --output pdf4.2 Few-shot 学习与示例构建
Few-shot 学习是一种通过示例引导 AI 理解任务的技术。你不需要用大量数据训练模型,只需提供几个精选的输入-输出示例,AI 就能快速掌握任务模式。
4.2.1 示例选择策略
示例的质量直接决定 Few-shot 学习的效果。好的示例应满足三个原则:
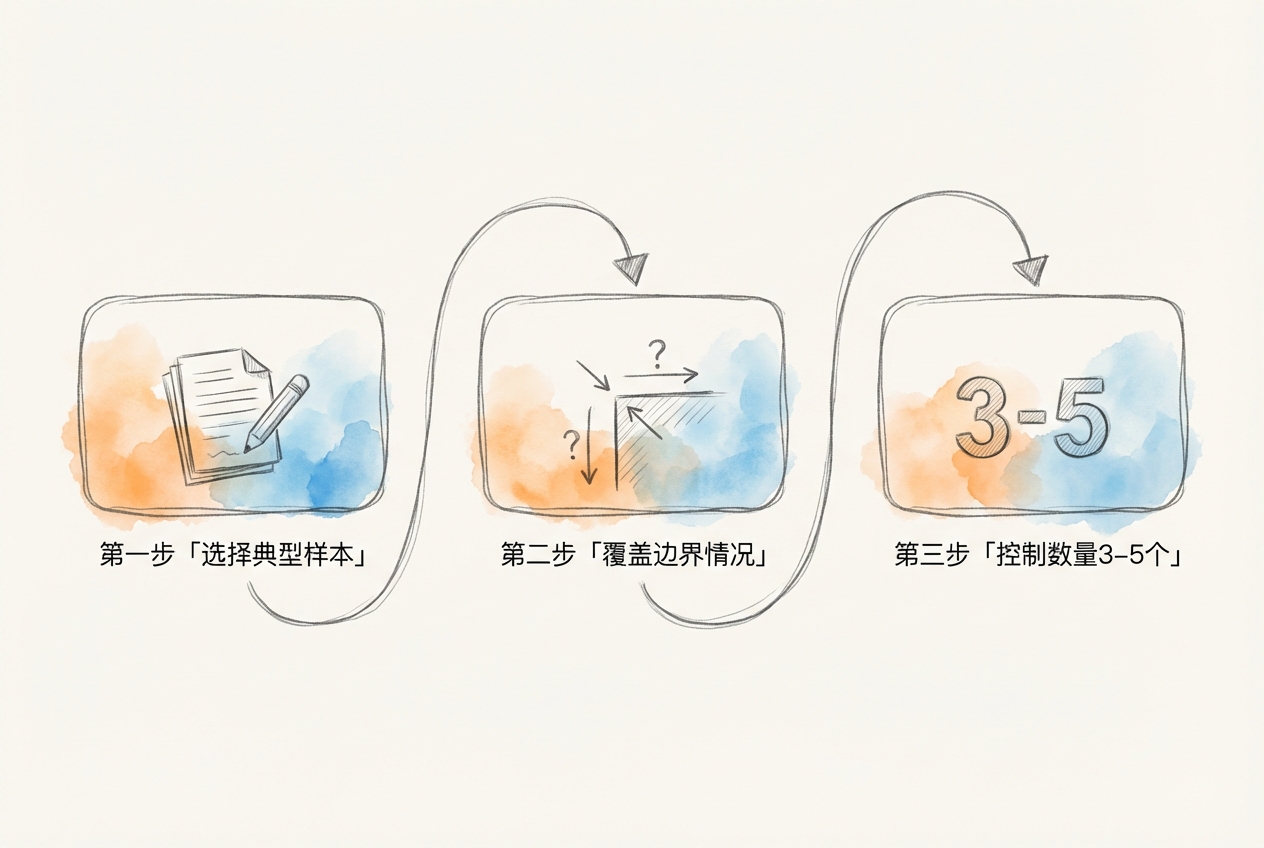
质量原则
示例必须准确、清晰、典型:
- 准确无误:示例的输入-输出映射必须正确
- 清晰明确:避免模糊或有歧义的表述
- 典型代表:能够反映任务的核心特征
- 格式一致:所有示例使用统一的格式
多样性原则
示例应覆盖任务的不同方面:
- 类别平衡:分类任务中,各类别应有相等的示例数
- 边界案例:包含一些非典型或边界情况
- 复杂度层次:从简单到复杂的示例组合
相关性原则
示例应与目标任务高度相关:
- 领域匹配:金融任务使用金融领域的示例
- 任务类型匹配:分类任务用分类示例,生成任务用生成示例
Few-shot 学习利用了大语言模型的「上下文学习」(In-Context Learning)能力。研究发现,当模型参数量超过某个临界点,模型就能从提示词中的示例归纳出任务规则,无需额外训练。
4.2.2 示例格式设计
示例格式的选择取决于任务类型。以下是四种常用格式:
基本输入-输出对格式(适合简单映射任务):
输入:苹果公司发布了新款 iPhone,市场反应热烈。
输出:积极
输入:公司第四季度亏损扩大,裁员 10%。
输出:消极带解释的格式(帮助模型理解判断逻辑):
输入:虽然一季度利润下滑 10%,但公司表示已采取成本控制措施。
分析:虽然短期利润下滑是负面消息,但有明确的改善计划。
输出:中性偏积极思维链格式(适合复杂推理任务,详见 4.2.3):
问题:某公司营收 100 亿,今年增长 20%,其中海外增长 50%。
已知海外占总营收 40%,计算海外市场营收。
让我们一步步思考:
步骤 1:今年总营收 = 100 × 1.2 = 120 亿
步骤 2:今年海外营收 = 120 × 40% = 48 亿
答案:48 亿元结构化提取格式(适合多字段提取任务):
文本:特斯拉 2024 年 Q3 营收 251.8 亿美元,同比增长 8%,净利润 21.7 亿。
提取结果:
- 公司名称:特斯拉
- 时间周期:2024 年 Q3
- 营收:251.8 亿美元
- 营收增长率:8%
- 净利润:21.7 亿美元4.2.3 动态示例构建与思维链推理
在实际应用中,示例并非总是静态预设的。动态示例构建根据用户输入的特征,实时选择或生成最相关的示例,从而提升 Few-shot 学习的效果。
动态示例构建的核心思路:
- 语义相似度匹配:根据用户输入,从示例库中检索语义最相近的示例
- 类别感知选择:如果已知输入的可能类别,选择该类别的典型示例
- 难度适配:根据问题复杂度选择相应难度的示例
示例检索流程:
用户输入 → 语义编码 → 相似度计算 → 选取 Top-K 示例 → 组装提示词在 Claude Code 的 Skill 中,可以通过以下方式实现动态示例:
## 示例库
本技能包含 20 个预设示例,按以下类别组织:
- 简单分类(5 个)
- 复杂推理(5 个)
- 边界案例(5 个)
- 混合类型(5 个)
## 示例选择规则
1. 如果用户问题简短明确,选择 2 个简单分类示例
2. 如果用户问题涉及多步骤分析,选择 2 个复杂推理示例
3. 始终包含 1 个边界案例作为参考思维链:一种特殊的动态示例技术
思维链(Chain of Thought, CoT)是动态示例构建的重要技术。它通过展示推理过程来引导 AI 解决复杂问题,可以显著提升复杂任务的准确率。
为什么 CoT 有效?
CoT 模拟了人类解决复杂问题的方式:将大问题分解为小步骤,逐步推进。研究表明,CoT 可将某些数学推理任务的准确率提升 4-400%。
Zero-shot CoT(最简单的实现):
只需在提示末尾添加「让我们一步一步思考」:
问题:小明有 15 本书,借给朋友 3 本,捐给图书馆 4 本。
后来又买了 7 本,卖掉 2 本。小明现在有多少本书?
请一步一步思考后回答。AI 会自动展开推理过程:
让我一步步计算:
1. 小明最初有 15 本书
2. 借给朋友后:15 - 3 = 12 本
3. 捐给图书馆后:12 - 4 = 8 本
4. 买了新书后:8 + 7 = 15 本
5. 卖掉后:15 - 2 = 13 本
答案:小明现在有 13 本书。Few-shot CoT(通过示例演示推理过程):
对于复杂任务,提供包含推理过程的示例效果更好:
示例:
问题:一个班有 32 名学生,女生比男生多 4 人。女生有多少人?
推理过程:
- 设男生有 x 人,则女生有 (x + 4) 人
- 男生 + 女生 = 总人数:x + (x + 4) = 32
- 2x + 4 = 32,解得 x = 14
- 女生人数 = 14 + 4 = 18
答案:女生有 18 人。
现在请解决:[新问题]- 适用场景:数学计算、逻辑推理、多步分析
- 不适用场景:简单查询、创意生成
- 示例数量:2-5 个示例通常足够
4.2.4 示例数量与质量权衡
示例数量的选择需要权衡多个因素:
| 任务复杂度 | 建议示例数 | 说明 |
|---|---|---|
| 简单分类 | 2-3 个 | 每个类别至少 1 个示例 |
| 中等复杂度 | 3-5 个 | 覆盖主要情况和边界案例 |
| 复杂推理 | 5-10 个 | 展示完整的推理过程 |
增加示例的好处:
- 提供更多模式供模型学习
- 覆盖更多边界情况
- 减少歧义
增加示例的代价:
- 消耗更多 token(增加成本和延迟)
- 可能超出上下文窗口限制
- 存在边际收益递减
研究表明(Brown et al., 2020, “Language Models are Few-Shot Learners”),主要性能提升发生在添加第 2 个示例之后,超过 5 个示例后收益显著递减。
实践建议:
- 从 2-3 个高质量示例开始
- 测试效果,不理想再增加
- 优先提升示例质量而非数量
- 注意示例的多样性和平衡性
4.3 输出格式控制
结构化输出是将 AI 的自由文本响应转化为机器可读格式的技术。在金融应用中,这一点尤为重要——无论是提取财务数据、生成分析报告,还是与下游系统集成,都需要可靠的格式控制。
4.3.1 结构化输出设计
结构化输出的核心价值:
- 将不可预测的文本转化为确定性数据
- 简化解析流程,便于与下游系统集成
- 减少模型幻觉的发生概率
- 提高输出的可靠性和一致性
格式选择策略:
| 输出格式 | 适用场景 | 优势 | 劣势 |
|---|---|---|---|
| JSON | API 集成、程序化解析 | 广泛支持、易于验证 | 不适合长文本 |
| XML | 文档结构、复杂嵌套 | 自描述性强、Claude 原生支持 | 冗余度高 |
| Markdown | 报告生成、人类阅读 | 人类可读、格式化渲染 | 机器解析复杂 |
| 表格 | 数据对比、指标展示 | 直观清晰 | 不支持嵌套 |
4.3.2 JSON 与 XML 格式生成
JSON 格式
JSON 是最常用的结构化输出格式。以下是金融数据提取的示例:
任务:从财务报告中提取关键指标,返回 JSON 格式。
字段说明:
- ticker: 股票代码(如 600519)
- period: 报告期(如 2024Q3)
- revenue: 营业收入(单位:亿元)
- net_profit: 净利润(单位:亿元)
- yoy_growth: 同比增长率
输出格式:
{
"ticker": "600519",
"period": "2024Q3",
"revenue": 398.5,
"net_profit": 195.3,
"yoy_growth": "+16.8%"
}
注意:
- 直接输出 JSON,不要使用 Markdown 代码块
- 确保 JSON 格式正确可解析防御性提示设计:
为了避免格式问题,可以在提示中添加明确的约束:
输出要求:
1. 直接输出有效的 JSON,不要使用代码块
2. 不要添加任何解释性文字
3. 响应必须以 "{" 开头,以 "}" 结尾
4. 确保所有字符串使用双引号
5. 数值不带引号XML 格式
Claude 对 XML 标签有特殊优化,使用 XML 可以清晰分隔提示的不同部分:
<task>金融新闻情感分析</task>
<context>
你是一位专业的金融分析师,需要分析以下新闻的市场情感。
</context>
<news>
某科技公司发布财报,营收超预期 15%,股价盘后上涨 8%。
</news>
<output_format>
请按以下结构输出:
<analysis>
<sentiment>positive/negative/neutral</sentiment>
<confidence>0.0-1.0</confidence>
<reasoning>判断理由</reasoning>
</analysis>
</output_format>XML vs JSON 选择建议:
| 场景 | 推荐格式 | 理由 |
|---|---|---|
| 简单数据结构 | JSON | 更简洁、广泛支持 |
| 复杂嵌套文档 | XML | 自描述性强、层次清晰 |
| Claude 专用应用 | XML | Claude 原生优化支持 |
| 需要程序处理 | JSON | 解析库更丰富 |
4.3.3 模板引擎集成
对于重复性强的报告生成任务,可以将 LLM 输出与模板引擎结合,实现高质量文档的快速生成。
模板引擎的工作原理:
- 预定义模板:在 Skill 中定义报告模板(Markdown/HTML)
- 变量占位:使用
{variable}标记待填充字段 - 数据填充:将 LLM 生成的结构化数据填入模板
- 格式渲染:生成最终报告
财务报告模板示例:
# {{company_name}} 财务分析报告
**报告期**: {{report_period}}
**生成时间**: {{generated_at}}
## 一、核心指标
| 指标 | 数值 | 同比变化 |
|------|------|----------|
| 营业收入 | {{revenue}} 亿元 | {{revenue_growth}} |
| 净利润 | {{net_profit}} 亿元 | {{profit_growth}} |
| 毛利率 | {{gross_margin}}% | {{margin_change}} |
## 二、财务比率
- **ROE**: {{roe}}%
- **ROA**: {{roa}}%
- **资产负债率**: {{debt_ratio}}%
## 三、分析结论
{{analysis_summary}}
---
*本报告由 AI 自动生成,仅供参考*在 Claude Code 中的应用:
Claude Code 可通过 Skill 实现模板集成:
---
name: report-generator
description: |
财务报告生成技能。结合模板生成标准化报告。
---
# 报告生成技能
## 工作流程
1. 从用户输入或数据源获取原始数据
2. 调用 LLM 提取结构化指标(JSON 格式)
3. 将 JSON 数据填充到报告模板
4. 输出格式化的完整报告
## 模板文件
模板存放在 `templates/financial_report.md`
## 输出要求
- 先输出结构化 JSON 数据
- 然后输出填充后的完整报告模板引擎的优势:
| 优势 | 说明 |
|---|---|
| 格式一致 | 所有报告遵循统一格式,提升专业性 |
| 减少幻觉 | 数据字段由 LLM 提取,文本框架由模板确定 |
| 易于维护 | 修改模板即可调整所有报告格式 |
| 降低成本 | 模板部分不消耗 token |
4.3.4 格式验证与错误处理
即使有明确的格式要求,AI 输出也可能出现问题。常见的格式失败原因及应对策略:
| 失败类型 | 检测方法 | 预防措施 |
|---|---|---|
| Token 截断 | 检查响应是否以 } 结尾 |
max_tokens 设置为预期长度的 1.5 倍 |
| Markdown 包装 | 检查是否包含 ``` |
提示中明确「不要使用代码块」 |
| 额外解释 | 检查首字符是否为 { |
提示中强调「直接输出 JSON,不要解释」 |
| 字段缺失 | 使用 JSON Schema 验证 | 提示中列出所有必填字段 |
迭代纠错策略:
当输出格式不符合预期时,可以要求模型自我纠正:
上一次输出有格式错误,请修正。
错误输出:
{之前的错误输出}
期望格式:
{正确的格式模板}
请只输出修正后的内容,不要任何解释。如果 AI 持续输出格式错误,检查以下几点: 1. 格式要求是否足够明确? 2. 是否提供了格式示例? 3. 是否禁止了额外解释文字? 4. max_tokens 是否足够?
4.4 意图路由
意图路由(Intent Routing)是智能体系统的「调度中心」。它负责分析用户意图,将请求分流到最合适的处理模块。这就像银行大厅的导询台——根据客户需求,引导他们去对公柜台、个人柜台或理财专区。
4.4.1 意图分类原理
意图分类有三种主要方法:
| 方法 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 规则匹配 | 关键词/正则匹配 | 简单快速、完全可控 | 难以处理同义词 | 意图边界清晰 |
| 语义相似度 | 向量相似度计算 | 处理同义表达 | 需要嵌入模型 | 表达多样化 |
| LLM 分类 | 大模型理解 | 最灵活准确 | 成本较高 | 复杂模糊场景 |
规则匹配示例:
规则配置:
账户查询意图:
关键词:余额、账户、存款、查询余额
转账意图:
关键词:转账、汇款、转钱、付款
贷款意图:
关键词:贷款、借款、利率、还款LLM 分类提示词:
你是一个金融领域的意图分类专家。请分析用户输入,识别其主要意图。
可选意图类别:
- account_inquiry: 账户查询(余额、交易记录)
- transfer: 转账汇款
- investment: 投资理财咨询
- complaint: 投诉反馈
- general: 一般性咨询
用户输入:{query}
请返回 JSON 格式:
{"intent": "意图类别", "confidence": 0.0-1.0}4.4.2 条件分流设计
简单的路由只需要单层分类,复杂系统可能需要多层级架构:
单层路由(意图类别少、边界清晰):
用户输入 → 路由器 → 目标处理器
├→ 账户服务处理器
├→ 转账处理器
├→ 贷款处理器
└→ 默认处理器多层级路由(复杂系统):
用户输入 → 一级路由(领域分类)
├→ 金融服务 → 二级路由
│ ├→ 账户服务
│ ├→ 贷款服务
│ └→ 投资服务
├→ 技术支持 → 二级路由
│ ├→ 账号问题
│ └→ 系统故障
└→ 通用咨询 → 默认处理器多层级路由的优点:
- 每层分类任务更简单,准确率更高
- 便于独立维护和扩展
- 可以对不同层使用不同的分类方法
条件分支路由:
除了意图,还可以根据其他条件动态选择路由:
| 条件类型 | 示例 | 路由决策 |
|---|---|---|
| 用户等级 | VIP 用户 | 优先路由到高级服务 |
| 情感倾向 | 负面情绪 | 路由到投诉处理或人工 |
| 任务复杂度 | 复杂问题 | 使用高性能模型 |
4.4.3 Skill description 触发机制
在 Claude Code 中,Skill 通过 description 字段与用户意图进行语义匹配,实现自动触发。
Skill 定义示例:
---
name: financial-analysis
description: |
财务报表分析技能。当用户提到以下内容时使用:
- 财务分析、财报分析、年报解读
- 财务指标、财务比率
- 盈利能力、偿债能力、运营效率
---
# 财务分析技能
## 核心能力
- 财务报表分析(三大报表)
- 财务指标计算和解读
- 行业对比分析
## 分析框架
[具体的分析方法...]description 撰写要点:
- 关键词覆盖:列举各种可能的触发表达
- 正向说明:说明什么情况应该触发
- 反向说明:说明什么情况不应该触发
description: |
财务报表分析技能。
应该触发的情况:
- 分析公司财报、解读年报、季报
- 计算财务指标、财务比率
不应该触发的情况:
- 股票买卖建议 → 使用投资咨询技能
- 宏观经济分析 → 使用经济分析技能4.4.4 多级路由架构
复杂的金融智能体系统通常需要多级路由。以金融问答为例:
一级意图分类体系:
| 意图类别 | 描述 | 示例表达 |
|---|---|---|
| 账户服务 | 账户相关查询和操作 | 查余额、开户、销户 |
| 转账汇款 | 资金转移操作 | 转账、汇款、收款 |
| 理财投资 | 投资理财咨询 | 基金推荐、收益查询 |
| 政策解读 | 政策影响分析 | 降息影响、监管变化 |
置信度阈值处理:
| 置信度范围 | 处理策略 |
|---|---|
| >= 0.8 | 高置信度:直接路由到目标模块 |
| 0.5 - 0.8 | 中置信度:确认后执行或选择性路由 |
| < 0.5 | 低置信度:请求用户澄清 |
澄清请求示例:
我不太确定您的需求,请问您是想:
1. 查询账户信息
2. 办理转账
3. 咨询理财产品
4. 其他服务
请输入数字选择或重新描述您的问题。4.5 Claude Code 初实践
本节将前面学习的提示词工程技术整合到 Claude Code 的实际应用中。
4.5.1 系统提示配置
Claude Code 采用分层提示架构,每层有不同的作用域和注入时机:
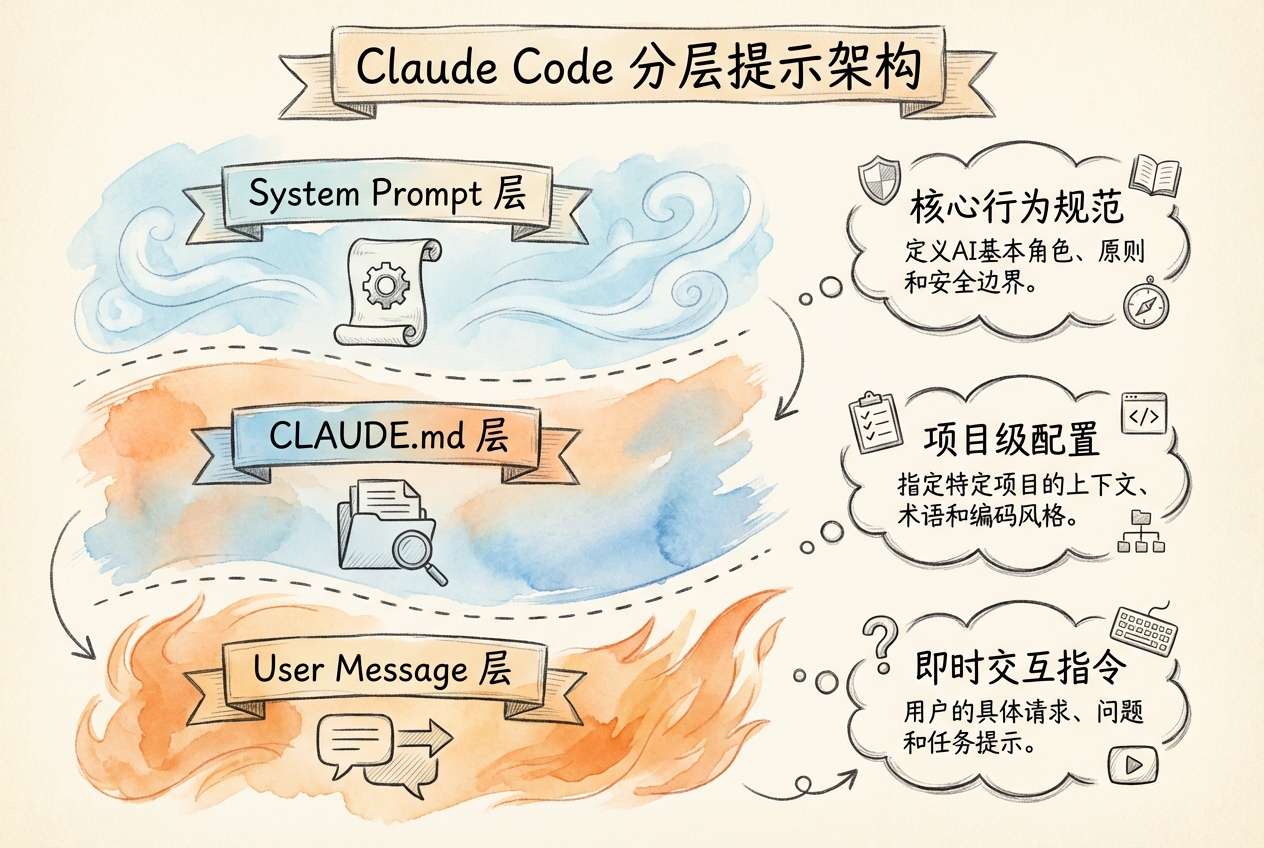
各层特点对比:
| 层级 | 机制 | 触发方式 | 典型用途 |
|---|---|---|---|
| 消息级 | CLAUDE.md | 自动加载 | 项目上下文 |
| 消息级 | Slash Commands | /command |
可重复工作流 |
| 消息级 | Skills | 模型判断 | 专业能力扩展 |
| 对话级 | Subagent | 委托触发 | 任务委派 |
Skill 目录结构:
.claude/skills/
└── financial-analysis/
├── SKILL.md # 核心定义文件(必需)
├── templates/ # 模板文件(可选)
│ └── report.md
└── examples/ # 示例(可选)
└── sample_analysis.md4.5.2 Few-shot 示例实现
在 Skill 中嵌入 Few-shot 示例:
---
name: sentiment-analysis
description: |
金融新闻情感分析技能。分析新闻的市场情感倾向。
---
# 金融情感分析技能
## 分析框架
判断金融新闻的情感倾向(积极/消极/中性)。
## 示例
输入:公司第四季度净利润同比增长 25%,超出市场预期。
情感:积极
置信度:90%
输入:受原材料价格上涨影响,公司毛利率环比下降 3 个百分点。
情感:消极
置信度:85%
输入:央行维持基准利率不变,符合市场普遍预期。
情感:中性
置信度:80%
## 边界案例
输入:公司宣布大规模裁员计划,预计年节省成本 10 亿元。
情感:中性
置信度:65%
分析:裁员是负面事件,但成本节省是正面影响,整体中性。4.5.3 输出格式控制
在 Skill 中定义输出格式:
---
name: financial-data-extraction
description: |
财务数据提取技能。从文本中提取结构化财务数据。
---
# 财务数据提取技能
## 输出格式
必须按以下 JSON 格式输出:
{
"company_info": {
"name": "公司名称",
"stock_code": "股票代码",
"report_period": "报告期"
},
"metrics": {
"revenue": {"value": 数值, "unit": "单位"},
"net_profit": {"value": 数值, "unit": "单位"},
"yoy_growth": 百分比数值
}
}
## 输出要求
- 直接输出 JSON,不要使用代码块
- 确保所有字符串使用双引号
- 数值不带引号
- 未提及的字段填 null4.5.4 意图路由实现
在 Claude Code 中,可以通过设计一个专门的路由 Skill 来实现意图分流:
---
name: financial-router
description: |
金融问题智能路由技能。当用户提出金融相关问题时,
自动分类并路由到合适的专业 Skill。
Use PROACTIVELY for any financial question.
---
# 金融问题路由技能
## 功能说明
本技能作为金融问题的入口路由器,负责:
1. 分析用户问题的意图
2. 提取关键实体
3. 路由到对应的专业 Skill
## 路由目标
| 意图类型 | 目标 Skill | 触发场景 |
|---------|-----------|----------|
| market-query | market-query | 价格、行情、涨跌幅 |
| financial-analysis | financial-analysis | 财报、财务指标 |
| policy-interpretation | policy-interpretation | 政策、监管 |
| general | 直接回答 | 概念解释、基础知识 |
## 路由决策格式
{
"intent": "路由目标",
"confidence": 0.0-1.0,
"reasoning": "分类理由",
"next_action": "调用的 Skill 或直接回答"
}配套案例
案例 4A:财报摘要三步生成
| 要素 | 说明 |
|---|---|
| 演示模式 | 提示链(Prompt Chaining)+ 思维链推理(CoT) |
| 案例简述 | 将财报分析分解为「数据提取 → 关键指标计算 → 摘要生成」三步 |
| 经济学映射 | 生产流程分工——每个环节专注单一任务 |
| 应用衔接 | 第 13 章研报生成系统的分层设计采用类似思路 |
| 预计耗时 | 20-30 分钟 |
为什么使用提示链?
财报分析涉及数据提取、数学计算、语言生成三种不同能力。将其拆分为三个独立步骤有以下优势:
- 降低单次推理复杂度:每个步骤专注于单一任务
- 提高可调试性:每步输出可独立验证
- 增强可控性:可以针对每步精确约束输出格式
三步处理流程:
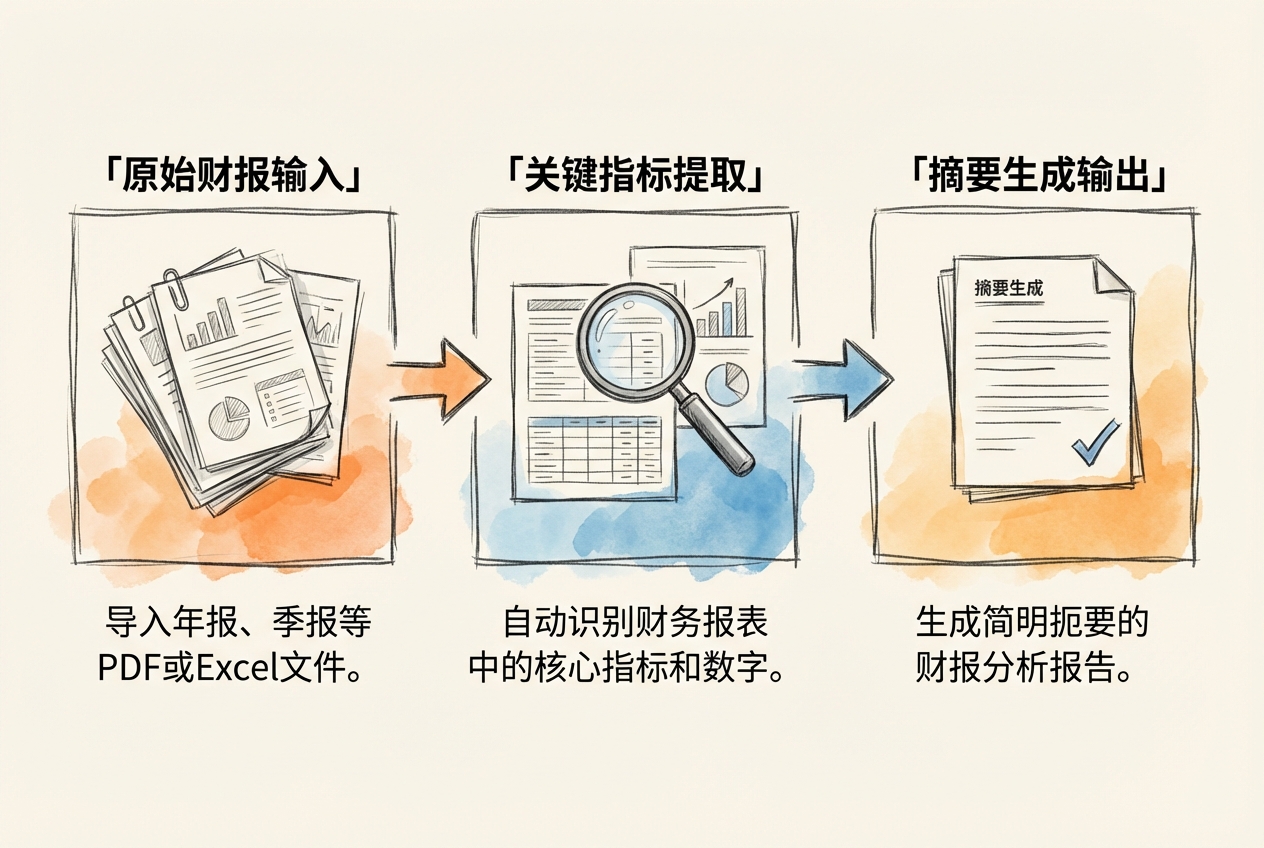
第一步:数据提取
你是一位专业的财务数据分析师,擅长从财务报告中提取关键数据。
## 任务
从以下财报文本中提取关键财务数据,输出结构化 JSON 格式。
## 财报文本
<financial_report>
贵州茅台 2024 年第三季度财务报告
报告期内,公司实现营业收入 1231.23 亿元,同比增长 16.02%;
归属于上市公司股东的净利润 606.80 亿元,同比增长 15.04%。
主要财务指标:
- 毛利率:92.71%
- 净利率:49.29%
截至报告期末:
- 总资产:2847.56 亿元
- 总负债:851.23 亿元
- 股东权益:1996.33 亿元
</financial_report>
## 输出格式
直接输出 JSON,不要使用代码块。
{
"company_info": {
"name": "公司名称",
"report_period": "报告期"
},
"income_statement": {
"revenue": {"value": 数值, "unit": "亿元"},
"revenue_yoy_growth": 百分比数值,
"net_profit": {"value": 数值, "unit": "亿元"},
"net_profit_yoy_growth": 百分比数值,
"gross_margin": 百分比数值,
"net_margin": 百分比数值
},
"balance_sheet": {
"total_assets": {"value": 数值, "unit": "亿元"},
"total_liabilities": {"value": 数值, "unit": "亿元"},
"shareholders_equity": {"value": 数值, "unit": "亿元"}
}
}第二步:关键指标计算(CoT)
你是一位资深财务分析师,需要根据提取的财务数据计算关键指标。
## 输入数据
[第一步输出的 JSON]
## 计算要求
请计算以下指标,并展示完整的计算过程:
1. 资产负债率 = 总负债 / 总资产 × 100%
2. ROE (净资产收益率) = 净利润 / 股东权益 × 100%
3. ROA (总资产收益率) = 净利润 / 总资产 × 100%
## 输出格式
对于每个指标,请按以下步骤展示:
1. 公式说明
2. 代入数据
3. 计算过程
4. 最终结果
现在开始计算,请一步一步思考:预期的 CoT 输出:
让我一步一步计算各项财务指标。
### 1. 资产负债率
**公式说明**:资产负债率 = 总负债 / 总资产 × 100%
**代入数据**:
- 总负债 = 851.23 亿元
- 总资产 = 2847.56 亿元
**计算过程**:
851.23 ÷ 2847.56 × 100% = 29.89%
**最终结果**:资产负债率 = 29.89%
### 2. ROE (净资产收益率)
**公式说明**:ROE = 净利润 / 股东权益 × 100%
**代入数据**:
- 净利润 = 606.80 亿元
- 股东权益 = 1996.33 亿元
**计算过程**:
606.80 ÷ 1996.33 × 100% = 30.40%
**最终结果**:ROE = 30.40%
### 3. ROA (总资产收益率)
**公式说明**:ROA = 净利润 / 总资产 × 100%
**代入数据**:
- 净利润 = 606.80 亿元
- 总资产 = 2847.56 亿元
**计算过程**:
606.80 ÷ 2847.56 × 100% = 21.31%
**最终结果**:ROA = 21.31%第三步:摘要生成
你是一位资深的证券分析师,需要撰写专业的财务分析摘要。
## 原始数据
[第一步输出的 JSON]
## 计算指标
[第二步的计算结果]
## 写作要求
### 结构要求
1. **核心要点**(1-2 句话概括整体表现)
2. **业绩亮点**(2-3 个正面指标,用数据支撑)
3. **关注风险**(1-2 个需要关注的问题)
### 风格要求
- 使用专业但易懂的语言
- 避免堆砌数据,突出关键信息
- 保持客观中立
- 总字数控制在 200-300 字预期输出:
**核心要点**
贵州茅台 2024 年第三季度业绩稳健增长,营收和利润均实现双位数增长,
盈利能力和资产质量保持行业领先水平。
**业绩亮点**
- **盈利能力突出**:ROE 达 30.40%,ROA 达 21.31%,远超白酒行业平均水平
- **财务结构稳健**:资产负债率仅 29.89%,财务风险可控
- **增长势头良好**:营收同比增长 16.02%,净利润同比增长 15.04%
**关注风险**
- 毛利率已处于行业极高水平(92.71%),继续提升空间有限
- 高端白酒消费受宏观经济影响,需关注消费复苏节奏Skill 配置示例:
在 .claude/skills/financial-report-analyzer/SKILL.md 中:
---
name: financial-report-analyzer
description: |
财报分析技能,支持三步生成财报摘要。
当用户提到以下内容时使用:
- 分析财报、解读财报、财报摘要
- 财务分析、业绩分析
- 提取财务数据、计算财务指标
---
# 财报分析技能
## 功能说明
本技能实现「数据提取 → 指标计算 → 摘要生成」三步财报分析流程。
## 使用方法
当用户提供财报文本时:
1. **第一步:数据提取**
- 从财报文本中提取结构化数据
- 输出 JSON 格式的财务数据
2. **第二步:指标计算**
- 基于提取数据计算关键比率
- 使用 CoT 展示计算过程
3. **第三步:摘要生成**
- 综合数据和指标生成分析摘要
- 包含业绩亮点、风险提示案例 4B:金融问题分类路由
| 要素 | 说明 |
|---|---|
| 演示模式 | 意图路由(Intent Routing) |
| 案例简述 | 根据用户问题类型自动路由到不同 Skill |
| 经济学映射 | 专业化分工——不同类型任务交给专业化模块处理 |
| 应用衔接 | 第 11 章舆情分析系统的多 Agent 协作基于类似路由逻辑 |
| 预计耗时 | 20-30 分钟 |
为什么需要意图路由?
用户问题类型多样,不同类型需要不同的处理方式:
- 行情查询:需要实时数据接口
- 财报分析:需要深度分析能力
- 政策解读:需要政策知识库
如果用单一提示处理所有类型,会面临以下问题:
- 提示词过长,消耗大量 token
- 专业度不足,难以在每个领域都表现出色
- 资源浪费,简单查询不需要复杂推理
路由架构:
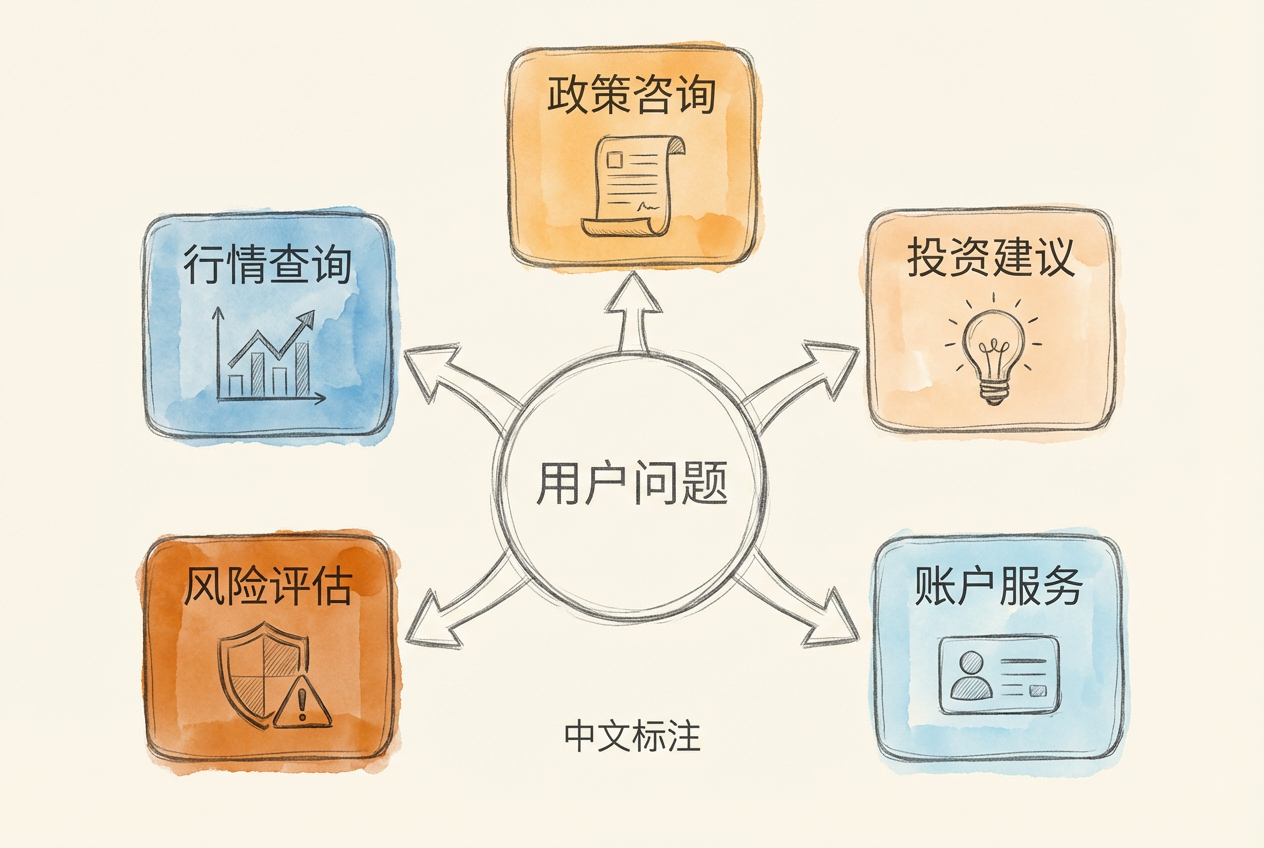
路由器 Skill 设计:
---
name: financial-router
description: |
金融问题智能路由技能。当用户提出金融相关问题时,
自动分类并路由到合适的专业 Skill。
---
# 金融问题路由技能
## 可用路由目标
### 1. market-query (行情查询)
**触发条件**:用户询问股票价格、指数行情、涨跌情况
**示例问题**:
- 茅台现在多少钱?
- 今天大盘涨了多少?
- 沪深 300 最新点位?
### 2. financial-analysis (财报分析)
**触发条件**:用户询问公司财务状况、业绩表现、财务指标
**示例问题**:
- 帮我分析茅台的财报
- 宁德时代的毛利率是多少?
- 这家公司盈利能力如何?
### 3. policy-interpretation (政策解读)
**触发条件**:用户询问政策内容、政策影响、监管规定
**示例问题**:
- 最新的 LPR 调整对股市有什么影响?
- 央行降准意味着什么?
### 4. general (通用咨询)
**触发条件**:不属于以上类别的金融相关问题
**示例问题**:
- 什么是市盈率?
- 基金和股票有什么区别?
## 路由规则
1. 仔细分析用户问题的核心意图
2. 匹配最合适的路由目标
3. 如果问题涉及多个类别,选择最主要的一个
4. 不确定时选择 general
## 输出格式
{
"intent": "路由目标",
"confidence": 0.0-1.0,
"reasoning": "简短说明分类理由"
}路由示例:
用户问题:茅台今天涨了多少?
{
"intent": "market-query",
"confidence": 0.95,
"reasoning": "用户询问股票涨跌幅,属于实时行情查询"
}用户问题:宁德时代去年的净利率和 ROE 是多少?
{
"intent": "financial-analysis",
"confidence": 0.92,
"reasoning": "用户询问财务指标,需要分析财报数据"
}用户问题:最近央行降准对银行股有什么影响?
{
"intent": "policy-interpretation",
"confidence": 0.88,
"reasoning": "用户询问货币政策的市场影响,属于政策解读"
}子 Skill 设计示例(行情查询):
---
name: market-query
description: |
股票行情查询技能,处理实时价格、涨跌幅、成交量等行情相关问题。
---
# 行情查询技能
## 功能范围
- 股票实时价格查询
- 指数行情查询
- 涨跌幅计算
- 成交量/成交额查询
## 回答模板
**{股票名称} ({股票代码})** 最新行情:
- 当前价格:{价格} 元
- 涨跌幅:{涨跌幅}%
- 成交量:{成交量} 手
- 成交额:{成交额} 亿元
## 注意事项
- 明确告知数据更新时间
- 提醒用户数据仅供参考
- 如无法获取实时数据,说明原因目录结构:
.claude/skills/
├── financial-router/
│ └── SKILL.md # 路由器 Skill
├── market-query/
│ └── SKILL.md # 行情查询 Skill
├── financial-analysis/
│ └── SKILL.md # 财报分析 Skill
└── policy-interpretation/
└── SKILL.md # 政策解读 Skill本章小结
本章介绍了提示词工程的四种核心技术:
- 系统提示设计:通过角色定义、任务边界和行为规范,建立 AI 的「岗位说明书」
- Few-shot 学习:通过精选示例引导 AI 理解任务模式,思维链技术可显著提升复杂推理的准确率
- 输出格式控制:使用 JSON/XML 等结构化格式,确保输出可靠、可解析
- 意图路由:基于意图分类实现任务分流,让专业模块处理专业问题
这些技术是后续章节的基础。无论是智能增强、工具使用还是多智能体协作,都需要扎实的提示词设计功底。
- 从简单开始:先掌握系统提示和格式控制,再学习 Few-shot 和路由
- 迭代优化:提示词设计是持续改进的过程,第一版很少完美
- 测试验证:用多个测试用例验证提示词效果,避免过拟合
- 记录版本:保存每个版本的提示词,方便回溯和对比