第 5 章 智能增强
- 理解 反思机制中的生产者-批评者架构,掌握其防止认知偏误的原理和四步反思流程
- 应用 Claude Code 的反思 Skill、CLAUDE.md 提示和 ultrathink 模式实现具有自我修正能力的智能体系统
- 应用 根据不同推理需求选择合适的推理技术(CoT、ToT、ReAct),并在实际金融问题中运用
- 分析 规划模式中的目标分解、约束管理、动态重规划等核心组件
- 应用 设计护栏机制与人在回路流程,明确风险阈值与人工介入条件
- 创造 设计并实现一个整合反思、推理、规划、护栏与 HITL 的完整智能体系统
- 评价 在给定的金融业务场景中评估不同智能增强模式的成本-收益权衡
想象这样一个场景:你是某券商的研究助理,需要在一小时内完成一份互联网行业龙头公司的投资价值分析。如果只是简单地让 AI 生成一份报告,结果往往不尽如人意——数据可能过时,推理可能跳跃,风险提示可能不足。
但如果让 AI 像一位经验丰富的分析师那样工作呢?先规划分析框架,再逐步收集数据,每完成一部分就自我审查,遇到不确定的地方主动请教人类,最后在输出前进行合规检查。这样的 AI 显然更可靠。
这就是本章要讲的智能增强。它不是给 AI 装上更多功能,而是让 AI 学会像人类专家那样思考和工作:深思熟虑、自我反省、有条不紊、安全可控。
智能增强包含五大核心模式:
- 反思:让 AI 审视自己的输出,发现问题并改进
- 推理:让 AI 展示思考过程,逐步解决复杂问题
- 规划:让 AI 分解目标,制定可执行的计划
- 护栏:在 AI 的输入输出环节设置安全检查
- 人在回路:在关键决策点引入人工确认
这五种模式不是孤立的技巧,而是相互配合的整体。一个成熟的金融智能体系统,往往需要综合运用多种模式。本章将逐一讲解每种模式的原理和实践,最后展示如何在 Claude Code 中将它们组合使用。
5.1 反思(Reflection)
反思模式让智能体具备自我审视和改进的能力。就像一位认真的研究员,写完报告后会反复检查数据是否准确、逻辑是否严密、风险提示是否充分。
5.1.1 生产者-批评者架构
反思模式最经典的实现是生产者-批评者架构(Producer-Critic Architecture)。这个设计将内容生成和内容评估分离开来,用两个不同的角色来完成任务。
生产者负责根据用户需求生成内容;批评者则站在审核专家的角度,评估内容质量并提出改进意见。两者交替工作,直到输出达到质量要求。
用金融行业的类比来说,这就像投行的研报审核流程:分析师(生产者)撰写初稿,质控部门(批评者)审核后提出修改意见,分析师修改后再次提交审核,如此往复直到通过。
这种架构的核心价值在于引入客观性。同一个人既写又审,容易陷入确认偏误——觉得自己写的都对。分离生产和评估角色后,评估者更容易发现问题。
在实际实现中,生产者和批评者可以是同一个 AI 模型的不同提示,也可以是两个独立的模型。关键是要让批评者有清晰的评估标准和批判性思维。

确认偏误(Confirmation Bias)是一种常见的认知偏差,指人们倾向于寻找支持自己观点的证据,而忽视反面证据。在投资分析中,分析师可能因为看好某只股票,就只关注利好消息而忽视风险因素。生产者-批评者架构通过角色分离来对抗这种偏误。
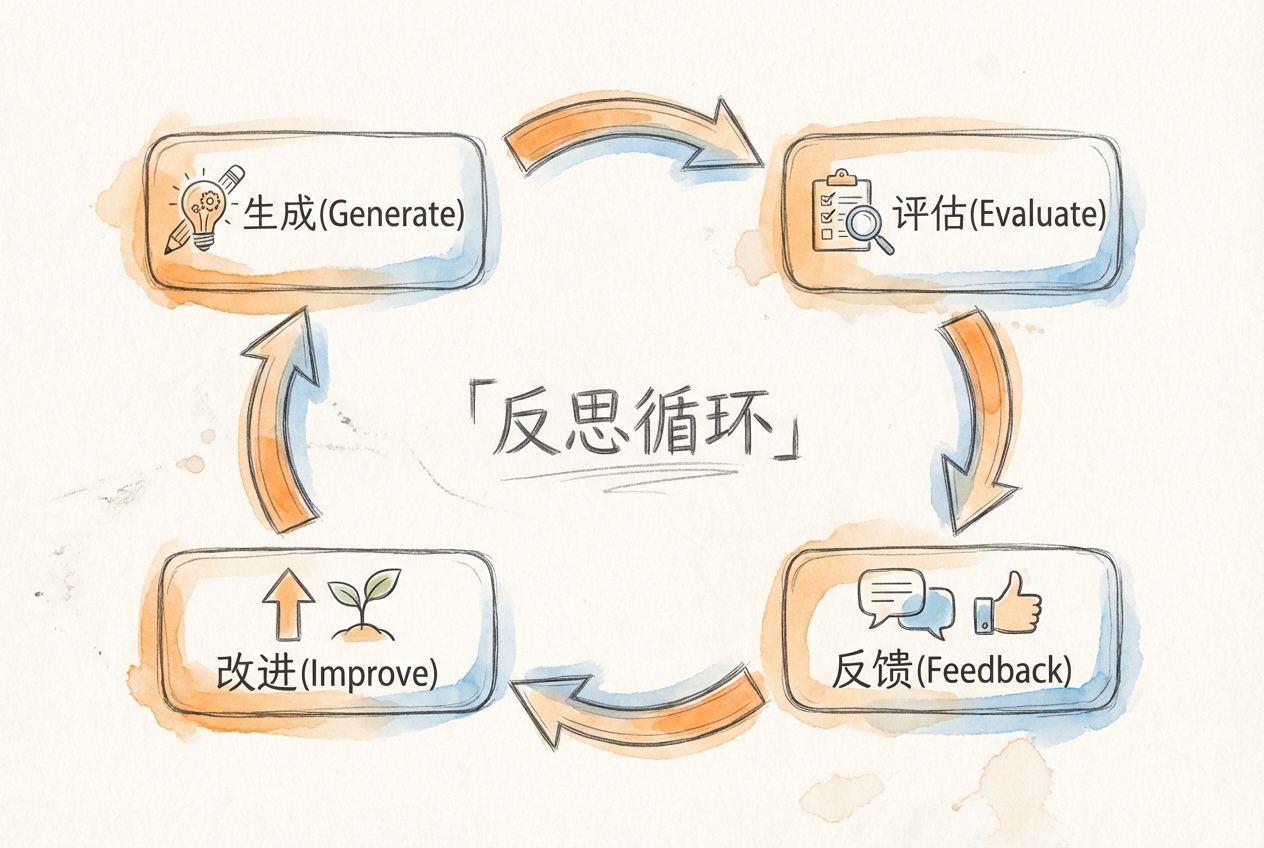
5.1.2 四步反思流程
一个完整的反思循环包含四个步骤:生成、审查、修订、验证。
第一步:生成(Generate)
根据用户需求产出初始内容。这一步不做质量假设,专注于完成任务。比如,分析某公司的财务状况,先生成一份包含杜邦分析的初稿。
第二步:审查(Review)
从多个维度评估生成内容的质量。常见的评估维度包括:
- 逻辑连贯性:推理过程是否合理?
- 数据准确性:引用的数据是否正确、是否最新?
- 完整性:是否遗漏了重要方面?
- 表达清晰度:是否容易理解?
审查结果需要结构化输出,包括质量评分、发现的问题列表、具体改进建议。
第三步:修订(Revise)
根据审查结果进行针对性修改。修订不是重写,而是精准解决审查中发现的问题。比如,审查发现风险提示不足,修订时就补充相应内容。
第四步:验证(Verify)
确认修订是否解决了发现的问题,判断是否达到质量阈值。如果通过验证,输出最终结果;如果仍有问题,返回第二步继续迭代。
这个循环通常重复 1-3 次。研究表明,经过反思迭代的输出质量平均提升 20%。但迭代次数超过 3 次后,边际收益明显递减。
5.1.3 自我批评提示设计
让 AI 进行有效的自我批评,关键在于提示词的设计。好的批评提示应该:
明确评估维度。不要只说检查一下有没有问题,而要列出具体的检查要点。例如,在金融分析场景中:
请从以下维度审核这份投资建议:
数据准确性:
- 财务数据是否来自最新财报?
- 市场数据是否为近期数据?
- 计算过程是否正确?
风险披露:
- 是否说明了可能的亏损?
- 是否提及了市场波动风险?
- 是否考虑了流动性风险?
合规检查:
- 是否避免了收益承诺表述?
- 是否有充分的风险提示?
请列出发现的所有问题,并按严重程度排序。鼓励批判性思维。提示词应该引导 AI 寻找问题,而不是确认正确性。可以使用这样的表述:假设这份分析存在问题,请找出可能的漏洞。
要求结构化输出。让批评结果便于后续处理。可以要求按问题类型分类,给出严重程度评级,并提供具体的修改建议。
对于经济金融专业学生来说,设计自我批评提示可以借鉴论文审稿的经验:好的审稿意见总是具体指出问题所在,而不是笼统地说需要改进。同样,好的批评提示需要明确告诉 AI 要检查什么、如何判断好坏。
5.1.4 反思深度与成本权衡
反思模式提升质量的同时也增加了成本。每一轮反思都意味着额外的 API 调用、更长的响应时间、更多的 token 消耗。
成本与质量的关系大致如下:
| 迭代次数 | 质量提升 | Token 成本 | 响应时间 | 使用建议 |
|---|---|---|---|---|
| 1 次 | +15-20% | 2x | 2x | 推荐用于常规任务 |
| 2-3 次 | +20-25% | 3-4x | 3-4x | 推荐用于重要任务 |
| 4-5 次 | +5-10% | 5-6x | 5-6x | 视任务重要性决定 |
| 5 次以上 | <5% | 7x+ | 7x+ | 不推荐 |
最佳实践是根据任务重要性选择反思深度:
- 高风险任务(如投资建议、合规审查):使用 2-3 轮反思
- 中等任务(如数据分析、报告初稿):使用 1-2 轮反思
- 低风险任务(如信息查询、格式转换):可以跳过反思
还有一种条件触发策略:只有当初始输出的置信度低于阈值时才启动反思。这样既保证了质量,又避免了对简单任务的过度处理。
案例 5A:投资建议自我审核(反思)
| 要素 | 说明 |
|---|---|
| 演示模式 | 反思(Reflection) |
| 案例简述 | 生成投资建议后,触发批评者角色审视风险披露是否充分、论据是否可靠。体验生产者-批评者架构的自我修正机制。 |
| 应用衔接 | 第 11 章舆情分析的情感判断复核、第 13 章研报的 Writer-Reviewer 迭代均采用反思模式 |
实践步骤:
第一步,请求生成投资建议:
请分析以下公司的投资价值并给出建议:
- 公司:示例科技股份有限公司
- 营业收入:50亿元,同比增长15%
- 净利润:5亿元,同比增长20%
- 市盈率:25倍
- 行业:软件服务第二步,触发自我批评:
请对上述投资建议进行严格自我审核:
1. 数据计算是否准确?
2. 结论是否有充分的数据支撑?
3. 是否遗漏了重要风险因素?
4. 用词是否避免了不当承诺?
列出发现的问题并给出改进版本。通过这个过程,你会发现初始建议可能存在风险提示不足、结论过于绝对等问题,经过反思后的版本会更加严谨。
5.2 推理技术(Reasoning)
推理技术的核心是让 AI 展示思考过程,而不是直接给出答案。这就像老师要求学生解题时写出步骤,而不只是给出最终结果。展示过程不仅让答案更可信,还便于发现和纠正中间环节的错误。
5.2.1 思维链(Chain-of-Thought)原理
思维链(Chain-of-Thought, CoT)是最基础也最实用的推理技术。它通过引导 AI 逐步展开推理过程,将复杂问题分解为一系列中间步骤。
触发 CoT 最简单的方式是在提示词中加入让我们一步一步思考。这句看似简单的指令能显著提升模型处理复杂问题的准确率,特别是数学计算和逻辑推理任务。
CoT 的四个核心特性:
- 问题分解:将复杂问题拆解为可管理的子步骤
- 过程透明:展示推理的每个环节,便于理解和验证
- 错误定位:如果结论有误,可以追溯到具体哪一步出了问题
- 通用适用:适用于算术、逻辑、常识等多种推理任务
在金融分析中,杜邦分析是 CoT 的典型应用场景。不要让 AI 直接说 ROE 是多少,而是让它逐步计算:
请使用链式思维分析该公司的盈利能力:
已知数据:
- 净利润:500万元
- 营业收入:5000万元
- 总资产:10000万元
- 股东权益:4000万元
第一步:计算净利润率
净利润率 = 净利润 / 营业收入 = 500 / 5000 = 10%
分析:10%的净利润率说明每100元收入转化为10元净利润。
第二步:计算资产周转率
资产周转率 = 营业收入 / 总资产 = 5000 / 10000 = 0.5次
分析:资产周转率0.5次,说明资产运营效率偏低。
第三步:计算权益乘数
权益乘数 = 总资产 / 股东权益 = 10000 / 4000 = 2.5
分析:权益乘数2.5,债务占总资产的60%。
第四步:计算ROE
ROE = 净利润率 × 资产周转率 × 权益乘数 = 10% × 0.5 × 2.5 = 12.5%
结论:该公司ROE为12.5%,主要由净利润率和财务杠杆驱动,资产周转效率有提升空间。这样的分析过程清晰可查,如果某个指标算错了,很容易发现是哪一步出了问题。
5.2.2 思维树(Tree-of-Thought)结构
思维树(Tree of Thought, ToT)是 CoT 的扩展。如果说 CoT 是沿着一条路径走到底,ToT 则是同时探索多条路径,选择最优的那条。
ToT 的核心组件:
- 思维生成:在每个节点生成多个候选方案
- 状态评估:对每个方案进行打分或投票
- 搜索算法:使用广度优先或深度优先策略探索
ToT 特别适合需要比较多个方案的决策问题,比如投资组合配置:
问题:100万元资金,在股票、债券、货币基金中如何配置?
思维树展开:
根节点:100万待配置资金
├── 方案A(激进型):股票70%,债券20%,货基10%
│ ├── 牛市情景(概率30%):预期收益+25%
│ ├── 震荡情景(概率40%):预期收益+5%
│ └── 熊市情景(概率30%):预期收益-15%
│ └── 期望收益 = 5.0%,波动性:高
│
├── 方案B(平衡型):股票40%,债券40%,货基20%
│ ├── 牛市情景:预期收益+15%
│ ├── 震荡情景:预期收益+6%
│ └── 熊市情景:预期收益-5%
│ └── 期望收益 = 5.4%,波动性:中
│
└── 方案C(保守型):股票20%,债券50%,货基30%
├── 牛市情景:预期收益+8%
├── 震荡情景:预期收益+5%
└── 熊市情景:预期收益+2%
└── 期望收益 = 5.0%,波动性:低
决策建议:
- 风险中性投资者:选择方案B(期望收益最高)
- 风险厌恶投资者:选择方案C(无负收益情景)ToT 的优势在于系统化对比,让决策有据可依。但它的计算成本比 CoT 高很多,适合重要决策而非日常任务。
上述思维树示例展示的是 ToT 的理想效果。在 Claude Code 中实际实现时,需要通过多次对话迭代:先让 AI 生成候选方案,再对每个方案分别评估,最后汇总对比。这意味着更多的 API 调用和更长的执行时间。
对于简单决策问题,直接使用 CoT 配合人工选择往往更高效。ToT 适合需要系统化对比多个方案的重要决策场景。
5.2.3 ReAct 模式(推理+行动)
ReAct(Reasoning and Acting)将推理与行动交替进行,让 AI 一边想一边做。这特别适合需要实时获取信息的任务。
ReAct 的基本循环是:Thought(思考)→ Action(行动)→ Observation(观察)→ Thought → …
与 CoT 的关键区别在于,CoT 完全依赖模型内部知识,而 ReAct 可以调用外部工具获取实时信息。这对金融分析至关重要,因为市场数据时刻变化。
问题:分析某只股票当前的投资价值
Thought: 需要了解该股票的基本面数据和当前估值水平
Action: 查询该股票最新财报数据
Observation: 2024年报显示营收增长15%,净利润增长20%...
Thought: 基本面不错,接下来需要看估值是否合理
Action: 查询当前股价和市盈率
Observation: 当前股价25元,动态市盈率18倍...
Thought: 需要与行业平均水平对比
Action: 查询行业平均市盈率
Observation: 行业平均市盈率22倍...
Thought: 估值低于行业平均,基本面良好,可以得出结论
Final Answer: 该股票基本面稳健,当前估值低于行业平均,具有一定投资价值...如何在 CoT、ToT、ReAct 之间选择?
- 如果问题是算的问题(财务计算、指标推导)→ 优先 CoT
- 如果问题需要比较多个方案 → 优先 ToT
- 如果问题需要查询实时数据 → 优先 ReAct
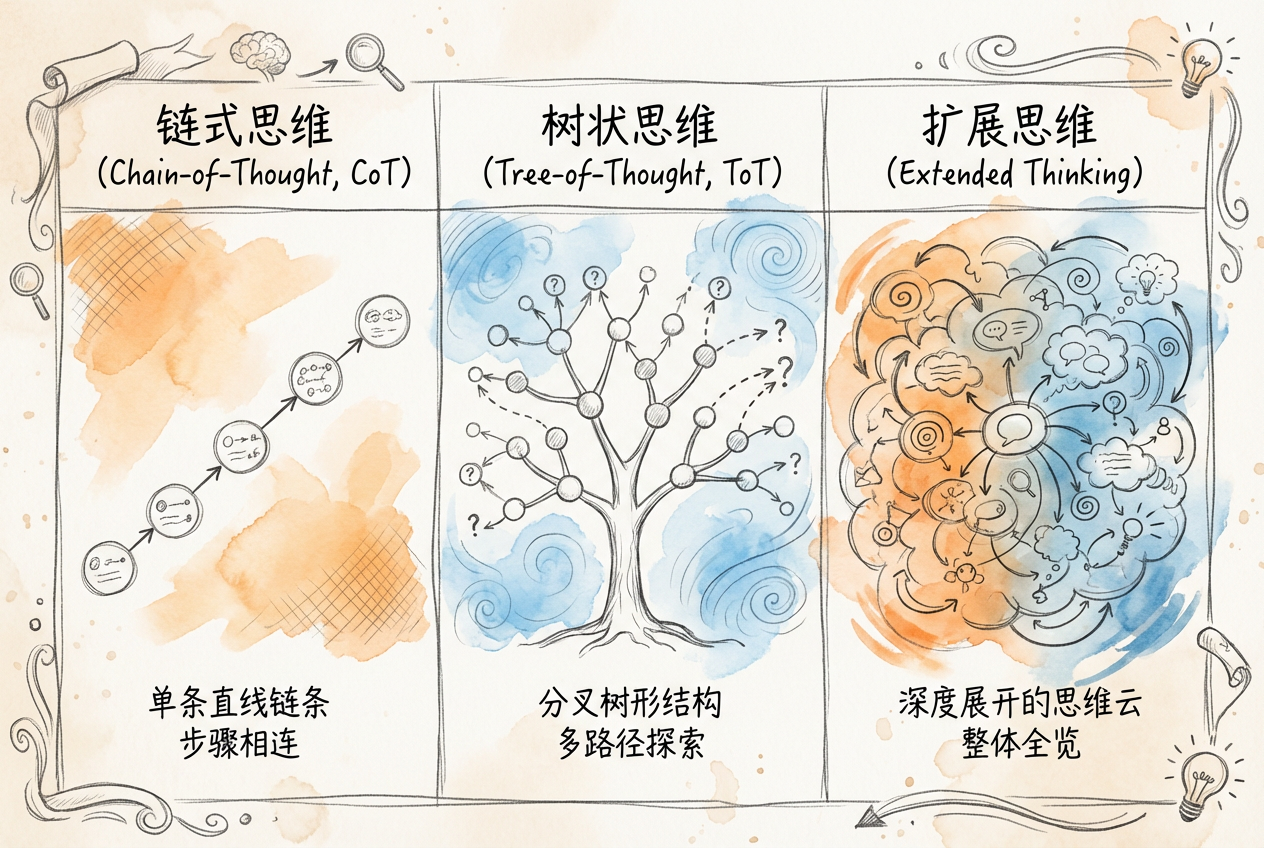
5.2.4 Extended Thinking 深度推理
Extended Thinking(扩展思考)是让模型在回答前进行更深入的内部思考。与标准回复相比,扩展思考模式允许模型花更多时间分析问题,从多个角度审视,进行自我检查。
Extended Thinking 是 Claude 3.5 及以上版本支持的特性。不同于普通对话的即时响应,扩展思考允许模型在内部进行更多推理步骤后再输出最终答案。思考过程对用户不可见,但输出结果更可靠。Claude Code 使用的正是支持此特性的 Claude 模型。
Claude Code 支持不同级别的思考深度,通过在提示词中加入特定关键词触发:
| 触发词 | 思考时间 | 适用场景 |
|---|---|---|
| think | 10-15秒 | 中等复杂度问题 |
| think hard | 20-30秒 | 需要多角度分析 |
| think harder | 30-45秒 | 架构设计、全面权衡 |
| ultrathink | 60秒以上 | 极其复杂的深度分析 |
ultrathink 是最深度的思考模式。使用时只需在提示词中加入这个关键词:
ultrathink 请分析这家公司的并购价值,需要考虑:
财务层面、战略层面、风险层面的综合评估ultrathink 模式会消耗更多 token,成本约为普通对话的 3-5 倍。建议只在真正需要深度分析的场景使用,日常简单任务使用普通模式即可。
案例 5B:财务比率分析推理(推理)
| 要素 | 说明 |
|---|---|
| 演示模式 | 推理技术(Reasoning) |
| 案例简述 | 给定企业财务数据,使用 Extended Thinking 模式(ultrathink)逐步推导杜邦分析。体验思维链如何提升复杂计算的准确性。 |
| 应用衔接 | 第 13 章研报生成的 Financial CoT Skill 采用类似推理技术 |
实践步骤:
ultrathink 请对以下公司进行完整的杜邦分析,逐步展示计算过程:
公司:示例制造有限公司
净利润:2000万元
营业收入:20000万元
总资产:50000万元
股东权益:20000万元
年初股东权益:18000万元
请计算并分析:
1. 净利润率及其含义
2. 总资产周转率及其含义
3. 权益乘数及其含义
4. ROE的分解计算
5. 与行业平均水平的对比分析
6. 改进建议通过 ultrathink 模式,你会看到模型进行深度思考的过程,包括对每个指标的多角度分析和综合判断。
5.3 规划(Planning)
规划模式解决的是如何把一个大目标拆成小步骤的问题。撰写一份研究报告这个目标太大了,需要分解为收集数据、分析财务、撰写各章节等具体任务。
5.3.1 目标分解与任务编排
目标分解是规划的第一步。好的分解应该满足 MECE 原则:相互独立(Mutually Exclusive)、完全穷尽(Collectively Exhaustive)。每个子任务不重叠,所有子任务加起来覆盖整个目标。
分解方法有几种:
- 简单提示分解:直接让 AI 列出完成任务的步骤
- 思维链分解:用 CoT 引导逐步拆解
- 人工引导分解:人类提供框架,AI 细化
任务编排需要考虑依赖关系。有些任务有先后顺序,比如必须先收集数据,才能进行分析;有些任务可以并行,比如分析财务和分析行业可以同时进行。
规划有两种主要模式:
ReAct 模式:边执行边规划。完成一步后,根据结果决定下一步。适合简单任务和不确定性高的场景。
Plan-and-Execute 模式:先制定完整计划,再逐步执行。适合复杂的多步骤任务。
| 维度 | ReAct | Plan-and-Execute |
|---|---|---|
| 规划方式 | 边执行边规划 | 先全局规划再执行 |
| 适用场景 | 简单任务、快速响应 | 复杂多步骤任务 |
| 灵活性 | 高,可即时调整 | 中,需重规划 |
| LLM 调用 | 每步都规划 | 规划阶段调用一次 |
5.3.2 约束管理与资源分配
规划不只是列任务清单,还需要管理约束条件。常见的约束包括:
- 时间约束:截止日期、各环节时间分配
- 资源约束:可用的工具、数据来源
- 质量约束:输出标准、合规要求
资源分配要考虑任务的优先级和复杂度。复杂任务分配更多时间,关键任务优先处理。
分层任务网络(Hierarchical Task Network, HTN)是一种经典的规划方法,源自人工智能领域的自动规划研究。HTN 的核心思想是将任务分为高层任务和底层任务:高层任务是抽象的目标(如「完成投资分析」),底层任务是具体的操作(如「计算市盈率」)。高层任务持续分解,直到所有任务都变成可直接执行的原子任务。这种层层分解的方式与人类处理复杂问题的思路一致。

5.3.3 动态重规划机制
静态计划在执行过程中常常需要调整。可能遇到的情况包括:
- 环境变化:数据源不可用,需要换一个
- 执行失败:某个步骤没有成功
- 新信息出现:发现了原计划没考虑到的因素
动态重规划的流程是:
- 监控执行:检测实际结果与预期是否一致
- 识别偏差:发现问题并评估影响
- 调整计划:修改后续步骤或整体方案
执行者可能是 AI 智能体、外部工具或人类操作员。如果执行者反馈失败或异常,规划器需要评估影响并决定下一步行动。
错误恢复是重规划的重要部分。当某个步骤失败时,可以尝试重试、使用替代方案或跳过该步骤。
初始计划:搜索"某公司2025年报" → 提取财务数据
执行结果:搜索无结果(2025年报尚未发布)
重规划:改为搜索"某公司2024年报" + 最新季报数据5.3.4 规划验证与执行监控
规划验证在执行前检查计划的可行性:
- 前置条件检查:所需资源是否就绪?
- 依赖关系验证:任务顺序是否合理?
- 完整性检查:是否覆盖所有必要步骤?
执行监控在过程中跟踪进度:
- 记录每个任务的开始和完成时间
- 标记任务状态(待处理、进行中、已完成)
- 及时发现和处理异常
案例 5C:研报写作规划(规划)
| 要素 | 说明 |
|---|---|
| 演示模式 | 规划(Planning) |
| 案例简述 | 输入撰写某公司行业分析报告目标,使用 TodoWrite 工具分解为章节大纲和写作步骤。体验目标分解与任务编排。 |
| 应用衔接 | 第 13 章研报生成系统的规划层(Planner Agent)直接应用此模式 |
实践步骤:
第一步,进入规划模式(按 Shift+Tab 两次),然后输入:
我需要撰写一份关于"云计算行业龙头公司"的深度投资分析报告。
请先制定详细的写作计划,不要开始写作。第二步,确认计划后,Claude 会创建任务列表:
任务状态追踪:
◐ 收集公司财务数据和行业资料
◯ 分析业务模式和竞争优势
◯ 评估财务状况和盈利能力
◯ 进行估值分析
◯ 撰写投资建议和风险提示
◯ 整理报告格式和附录第三步,切换到执行模式,按计划逐步完成各项任务,观察任务状态的更新。
5.4 护栏机制(Guardrails)
护栏机制在 AI 系统的输入、处理、输出各环节设置检查点,将不可控的生成行为转化为可预测、可审计、可干预的受控过程。
护栏的核心目标不是限制 AI 的能力,而是建立可信边界。就像银行的风控系统,不是阻止交易,而是确保交易安全合规。
5.4.1 输入验证与过滤
输入护栏在用户请求到达 AI 之前进行检查,具有三大价值:
- 成本控制:避免无效或恶意请求消耗资源
- 安全防护:过滤恶意指令和敏感话题
- 质量控制:确保输入符合预期格式
常见的输入验证包括:
长度限制:防止过长输入导致的问题
敏感词过滤:识别和处理敏感内容
格式验证:确保输入符合预期格式
Prompt 注入防护:防止恶意用户通过精心构造的输入操纵 AI 行为
Prompt 注入是一种安全威胁,攻击者试图通过输入忽略上述指令之类的内容来改变 AI 的行为。有效的输入护栏需要识别并过滤这类尝试。
5.4.2 输出校验与拦截
输出护栏对 AI 的最终输出进行验证,确保:
- 内容安全:不含有害或不当内容
- 隐私保护:不泄露敏感信息
- 格式正确:输出符合预期结构
在金融场景中,输出校验尤其重要。投资建议需要检查:
- 是否存在收益承诺(如保证收益、稳赚不赔)
- 是否有充分的风险提示
- 数据引用是否准确
- 用词是否合规
当检测到问题时,输出护栏可以采取不同策略:
- 拦截:完全阻止输出,返回错误提示
- 示例:检测到「保证收益 20%」表述 → 拦截输出,提示「包含违规表述,无法输出」
- 修正:自动修改问题内容
- 示例:将「稳赚不赔」自动替换为「历史表现稳健,但不保证未来收益」
- 标记:输出内容但附加警告信息
- 示例:输出内容前加上「本建议基于历史数据,投资有风险,需谨慎决策」
5.4.3 风险阈值设定
风险阈值决定了什么情况触发护栏干预。常见的阈值类型:
置信度阈值:当 AI 输出的置信度低于阈值时触发审核
置信度 >= 0.95 → 自动通过
置信度 0.80-0.94 → 标记为需复核
置信度 < 0.80 → 拦截,升级处理金额阈值:在金融场景中按交易金额设定风控级别
金额 < 1万 → 自动处理
金额 1-10万 → 需要一级审核
金额 > 10万 → 需要二级审核内容类型阈值:对不同类型的内容采用不同标准
阈值设定需要平衡安全性和效率。阈值过严会导致大量误拦截,影响用户体验;阈值过松则可能放过风险内容。

有限理性(Bounded Rationality)是诺贝尔经济学奖得主赫伯特·西蒙提出的概念。他认为,由于信息不完全和认知能力有限,人类无法做出完全理性的决策。AI 同样有能力边界,护栏机制正是通过规则约束来弥补这种边界,防止 AI 在超出能力范围时犯错。
5.4.4 异常处理与回退策略
当护栏检测到问题或系统发生异常时,需要优雅地处理:
重试策略:对于临时性故障,可以尝试重新执行。常用指数退避策略——每次重试的等待时间翻倍。
降级处理:当主服务不可用时,切换到备用方案。比如,复杂模型不可用时切换到简单模型。
安全回退:当无法确定安全的处理方式时,选择保守行为。宁可拒绝也不冒险执行。
异常处理决策树:
检测到异常
├── 是否为临时性故障?
│ ├── 是 → 重试(最多3次)
│ └── 否 ↓
├── 是否有降级方案?
│ ├── 是 → 使用降级方案
│ └── 否 ↓
└── 安全回退:
- 终止操作
- 记录日志
- 通知用户案例 5D:交易建议限额护栏(护栏机制)
| 要素 | 说明 |
|---|---|
| 演示模式 | 护栏机制(Guardrails) |
| 案例简述 | 使用 Hooks 机制实现交易建议的风险检查:单笔金额上限、持仓比例上限、高风险资产限制。体验 PreToolUse 拦截与 PostToolUse 校验。 |
| 经济学映射 | 有限理性——通过规则约束弥补能力边界 |
| 应用衔接 | 第 12 章信号分析系统的 risk-check Hook 直接应用此模式 |
实践步骤:
设计一个交易护栏,检查以下规则:
护栏规则:
1. 单笔交易金额不超过10万元
2. 单只股票持仓比例不超过20%
3. ST股票禁止买入
4. 总仓位不超过账户资产的80%测试护栏:
请帮我分析是否应该买入以下股票:
股票:*ST示例(代码 600XXX)
计划买入金额:15万元
当前账户总资产:50万元观察护栏如何识别出: - 金额超过单笔限额(15万 > 10万) - 股票带有 ST 标识(禁止买入) - 持仓比例过高(15万/50万 = 30% > 20%)
并给出相应的风险提示和替代建议。
5.5 人在回路(Human-in-the-Loop, HITL)
人在回路是一种 AI 系统设计模式,在关键决策点引入人工确认。AI 负责执行,人类负责决策——在自动化效率和决策安全之间找到平衡。
5.5.1 人工介入触发条件
不是所有操作都需要人工介入。判断是否需要 HITL,可以从以下维度考虑:
| 维度 | 高风险(需人工) | 低风险(可自动) |
|---|---|---|
| 错误后果 | 不可逆、高损失 | 可回滚、低影响 |
| AI 置信度 | < 0.8 | >= 0.95 |
| 任务复杂度 | 多因素、需判断 | 规则明确 |
| 合规要求 | 涉及监管 | 无特殊要求 |
置信度分层是常用的触发策略:
置信度 >= 0.95 → 自动执行
置信度 0.80-0.94 → 人工复核
置信度 < 0.80 → 升级处理或拒绝这种方法的效果: - 减少误报和漏报高达 50% - 长期准确率可达 98-99% - 随着系统从人工反馈中学习,人工工作量持续降低

5.5.2 审批流程设计
常见的 HITL 交互模式:
审批确认模式:AI 生成方案,人工决定是否执行
AI: 即将执行数据库备份操作,预计耗时30分钟。
[确认执行] [取消] [稍后提醒]编辑修正模式:AI 生成初稿,人工编辑后继续
AI: 以下是投资建议初稿,请您审阅并修改:
[建议内容]
[继续] [编辑后继续] [重新生成]信息补充模式:AI 遇到不确定情况,请求补充信息
AI: 分析过程中需要确认以下信息:
1. 您的风险偏好等级是?
2. 投资期限预期多长?审批流程设计要点: - 清晰的上下文:让审批者了解当前状态和操作影响 - 明确的选项:提供清晰的决策选项 - 合理的超时:设置默认行为或自动提醒
5.5.3 责任边界划分
HITL 系统中,AI 和人类的责任需要清晰划分:
| AI 负责 | 人类负责 |
|---|---|
| 数据处理、模式识别 | 创造性判断、伦理决策 |
| 重复性、标准化任务 | 最终审批、合规确认 |
| 实时监控、初筛 | 异常情况最终裁定 |
| 方案生成、建议 | 战略方向、价值判断 |
核心原则:AI 作为工具,人类作为最终责任主体。
这意味着: - AI 的输出是建议,不是决定 - 人工复核是流程必经步骤 - 出现问题时可追溯决策链条 - 人类对最终结果负责
在金融行业,许多操作有监管合规要求。投资建议必须符合投资者适当性原则,大额交易需要授权审批。HITL 不仅是技术选择,往往也是合规必需。设计系统时要了解相关法规要求。
5.5.4 人机协作效率优化
HITL 引入了人工环节,可能影响效率。优化策略包括:
使用主动学习:只在模型不确定时请求人工输入,减少不必要的干预
建立反馈循环:收集人类纠正数据,定期优化模型,提升 AI 自主能力
优化审批界面: - 提供清晰的上下文信息 - 预设选项减少输入成本 - 支持批量审核操作(当多个相似请求在短时间内累积时,可合并为一次审批)
监控关键指标: - 上报频率(应逐渐降低) - 响应时间 - 用户满意度 - 决策一致性
渐进式自动化路径:
第一阶段:HITL(保守)
所有决策需人工确认
第二阶段:HITL(优化)
低风险自动执行,中高风险人工确认
第三阶段:HOTL(监督)
Human-on-the-Loop(人在环外监督)
大部分自动执行,人工监控异常,只在系统告警时介入
第四阶段:自适应自动化
系统自动调整阈值,人工只处理复杂情况案例 5E:大额交易人工审批(HITL)
| 要素 | 说明 |
|---|---|
| 演示模式 | 人在回路(Human-in-the-Loop) |
| 案例简述 | 当交易建议金额超过阈值时,触发 AskUserQuestion 请求人工确认。体验关键决策点的人机协作机制。 |
| 经济学映射 | 决策权配置——高风险决策保留人类最终决定权 |
| 应用衔接 | 第 12 章信号分析、第 13 章研报生成的关键节点均设置人工审批 |
实践步骤:
模拟一个需要人工确认的场景:
请帮我分析一个投资方案:
计划投资金额:80万元
投资标的:某科技股ETF
当前账户资产:100万元观察 AI 如何识别这是一个高风险决策(单笔金额大、仓位比例高),并触发人工确认:
AI: 检测到高风险投资请求,需要您的确认:
决策要点:
- 投资金额:80万元(占账户80%)
- 风险等级:中高风险
- 流动性:ETF流动性良好,可随时赎回
风险提示:
- 仓位集中度较高,波动风险大
- 建议分批建仓,降低择时风险
请确认您的选择:
[确认全额投资] [调整为分批投资] [取消]用户确认后,记录决策链条以便审计追溯。
5.6 Claude Code 增强实践
前面五节讲解了智能增强的原理,本节展示如何在 Claude Code 中落地实践。Claude Code 提供了丰富的工具和机制,让这些模式变得易于使用。
5.6.1 反思机制实现
在 Claude Code 中实现反思有三种方式:
方式一:Self-Critique Prompts 嵌入 CLAUDE.md
在项目的 CLAUDE.md 文件中加入反思指令,让每次输出都经过自我检查:
## 输出质量规范
每次生成内容后,请执行以下自我审查:
1. 检查数据准确性:引用是否正确、是否最新
2. 检查逻辑完整性:推理是否有跳跃
3. 检查风险披露:是否充分说明了风险
4. 检查用词合规:是否避免了不当承诺
如发现问题,自行修正后输出。方式二:专用反思 Skill
创建一个专门用于反思的 Skill,在需要时调用:
# Skill: 财务分析自我审查
## 触发条件
当完成财务分析相关输出后
## 审查维度
- 计算准确性:各指标计算是否正确
- 数据时效性:使用的是否是最新数据
- 分析完整性:是否涵盖关键维度
- 结论支撑度:结论是否有充分依据
## 输出格式
列出发现的问题和改进后的版本Skill 创建步骤:
- 在项目根目录创建
.claude/skills/目录(如不存在) - 创建 Skill 文件
.claude/skills/financial-self-review.md - 写入上述内容
- 使用时在提示词中明确提及:「使用财务分析自我审查 Skill 检查这份报告」
如果 Claude 没有自动使用该 Skill,尝试: 1. 确认文件名和路径正确 2. 在提示词中明确提及 Skill 名称 3. 重启 Claude Code 会话
方式三:ultrathink 深度反思
对于重要输出,使用 ultrathink 进行深度反思:
ultrathink 请对上述分析进行深度审查,从数据、逻辑、风险、合规四个维度检查,列出所有可能的问题。5.6.2 推理技术配置
Extended Thinking 模式
使用思考关键词触发深度推理:
ultrathink 请分析这家公司的估值是否合理,需要考虑:
- 历史估值区间
- 可比公司估值
- 成长性溢价
- 风险折价推理 Skill 模板
创建结构化的推理 Skill:
# Skill: 投资价值分析
## 分析框架
### 第一步:基本面分析
- 业务模式
- 竞争优势
- 财务状况
### 第二步:估值分析
- 绝对估值
- 相对估值
- 安全边际
### 第三步:风险评估
- 业务风险
- 财务风险
- 市场风险
### 第四步:综合结论
- 投资评级
- 目标价格
- 关键假设ReAct 模式实现
结合工具调用实现 ReAct:
请使用ReAct模式分析这只股票,每一步都说明你的思考,然后执行相应操作。
可用工具:
- 搜索财务数据
- 查询行业信息
- 计算估值指标
请按 Thought → Action → Observation 的格式展开分析。5.6.3 规划工具使用
TodoWrite 工具
TodoWrite 是 Claude Code 内置的任务管理工具,用于分解和跟踪复杂任务:
任务状态符号:
◯ pending(待处理)
◐ in_progress(进行中)
● completed(已完成)适用场景: - 复杂的多步骤任务(3 个以上步骤) - 涉及多个文件修改的操作 - 需要系统化跟踪进度的项目
使用示例:
我需要完成以下任务:
1. 收集公司财务数据
2. 进行杜邦分析
3. 对比行业水平
4. 撰写分析报告
请创建任务列表并开始执行。Plan Mode 规划模式
按 Shift+Tab 在不同模式间循环切换。模式切换顺序:
default → acceptEdits → plan → bypassPermissions → default切换时,Claude 会在界面显示当前模式。进入 Plan Mode 后,Claude 会显示 Plan Mode 标识。
- 1 次 Shift+Tab:进入 acceptEdits(自动接受编辑)
- 2 次 Shift+Tab:进入 plan(只读规划模式)
- 3 次 Shift+Tab:进入 bypassPermissions(跳过所有确认,需安全环境)
- 4 次 Shift+Tab:返回 default(每次确认)
建议在复杂任务开始前,先按 2 次 Shift+Tab 进入 Plan Mode 制定方案。
在 Plan Mode 下,Claude 只进行只读操作和规划分析,不会执行写操作。
Plan Mode 工作流: 1. 分析任务需求 2. 读取相关代码和文件 3. 制定详细计划 4. 等待用户确认 5. 确认后切换到执行模式
最佳实践:复杂任务先进入 Plan Mode 制定方案,确认后再执行,避免方向错误导致返工。
5.6.4 护栏机制配置
Hooks 机制
Claude Code 的 Hooks 允许在特定事件发生时执行自定义逻辑:
| 事件类型 | 触发时机 | 用途 |
|---|---|---|
| PreToolUse | 工具执行前 | 验证参数、阻止危险操作 |
| PostToolUse | 工具执行后 | 格式化输出、记录日志 |
| Stop | 响应结束时 | 任务完成统计 |
| Notification | 发出通知时 | 外部告警集成 |
Hooks 匹配规则
matcher 字段支持以下匹配模式:
- 精确匹配:
"Bash"匹配 Bash 工具的所有调用 - 通配符匹配:
"*"匹配所有工具 - 参数匹配:
"Bash(rm:*)"匹配包含rm命令的 Bash 调用 - 正则匹配:
"Bash(/rm\\s+-rf/)"使用正则表达式匹配(注意 JSON 中反斜杠需转义)
Hooks 通过 .claude/settings.json 配置:
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "python ~/.claude/hooks/check_command.py"
}
]
}
]
}
}审计日志示例
记录所有工具调用,便于事后审计:
{
"hooks": {
"PreToolUse": [
{
"matcher": "*",
"hooks": [
{
"type": "command",
"command": "echo \"$(date) PRE: $CLAUDE_TOOL_NAME\" >> ~/.claude/audit.log"
}
]
}
],
"PostToolUse": [
{
"matcher": "*",
"hooks": [
{
"type": "command",
"command": "echo \"$(date) POST: $CLAUDE_TOOL_NAME\" >> ~/.claude/audit.log"
}
]
}
]
}
}5.6.5 人在回路实现
权限控制系统
Claude Code 提供分层的权限控制:
| 模式 | 说明 |
|---|---|
| default | 首次使用每个工具时提示权限 |
| acceptEdits | 自动接受文件编辑权限 |
| plan | 计划模式 - 只分析不执行 |
| bypassPermissions | 跳过所有权限提示(需安全环境) |
切换方式:按 Shift+Tab 在模式间循环切换。
工具权限配置
允许特定工具自动执行:
claude --allowedTools "Read" "Grep" "Glob"阻止危险工具:
claude --disallowedTools "Bash(rm:*)" "Bash(sudo:*)"AskUserQuestion 机制
Claude 可以主动暂停执行并询问用户:
场景:执行敏感操作前
Claude: 即将删除 /data/old_logs 目录下所有文件,共 1,234 个。
确认执行吗?
[确认] [取消] [查看文件列表]这种交互让用户保持对关键操作的控制权。
5.6.6 多模式组合实践
实际任务往往需要组合使用多种增强模式。以下是一个完整的工作流示例:
场景:完成一份投资分析报告
第一步:Plan Mode + ultrathink(深度规划)
进入 Plan Mode,请求:
ultrathink 分析"某公司投资价值"这个任务,制定详细的分析框架和写作计划
第二步:TodoWrite(任务分解)
确认计划后,创建任务列表:
◐ 收集财务数据和行业资料
◯ 分析业务模式和竞争优势
◯ 评估财务状况
◯ 进行估值分析
◯ 撰写投资建议
第三步:CoT + 反思(执行分析)
逐个完成任务,使用链式思维展示分析过程
每完成一部分,进行自我审查
第四步:护栏检查(合规验证)
输出前检查:
- 无收益承诺表述
- 风险提示充分
- 数据来源标注
第五步:HITL(人工确认)
Claude: 报告初稿已完成。请确认:
[定稿输出] [需要修改] [重新分析]| 阶段 | 使用的增强模式 | 作用 |
|---|---|---|
| 规划 | Plan Mode + ultrathink | 深度思考,制定全面计划 |
| 分解 | TodoWrite | 任务拆解,进度跟踪 |
| 分析 | CoT + 反思 | 系统推理,质量保证 |
| 检查 | 护栏机制 | 合规验证,风险控制 |
| 确认 | HITL | 人工把关,最终决策 |
| 任务类型 | 推荐组合 |
|---|---|
| 多步骤实现 | TodoWrite + Plan Mode |
| 复杂调试 | ultrathink + 反思 |
| 安全敏感操作 | Hooks + HITL |
| 长期项目 | TodoWrite + CLAUDE.md + Hooks |
本章小结
本章介绍了智能增强的五大核心模式及其在 Claude Code 中的实践应用。
反思模式通过生产者-批评者架构和四步反思循环,让 AI 具备自我审视和改进能力。对于金融分析等高风险任务,2-3 轮反思可显著提升输出质量。
推理技术包括链式思维(CoT)、思维树(ToT)、ReAct 和扩展思考四种方法。CoT 适合顺序推理,ToT 适合方案对比,ReAct 适合需要实时数据的任务,ultrathink 适合复杂决策。
规划模式将复杂目标分解为可执行的子任务,支持动态重规划以应对执行中的变化。Claude Code 的 TodoWrite 和 Plan Mode 是规划的有力工具。
护栏机制在输入、处理、输出各环节设置安全检查,通过 Hooks 实现自动化的风险控制。金融场景中的限额控制、合规检查都属于护栏范畴。
人在回路在关键决策点引入人工确认,平衡自动化效率与决策安全。置信度分层和渐进式自动化是优化 HITL 效率的有效策略。
这五种模式不是孤立的技巧,而是相互配合的整体。一个成熟的金融智能体系统,往往需要综合运用多种模式:规划阶段用 Plan Mode + ultrathink,执行阶段用 CoT + 反思,全程配置护栏和 HITL。
核心设计原则: - 先规划后执行 - 分层防御 - 最小权限 - 持续反馈 - 人类最终责任
掌握这些模式后,你就具备了设计可靠金融智能体系统的基础能力。下一章我们将学习记忆管理,探讨如何让智能体具备长期记忆能力。